一个语音克隆,支持微调的 TTS 工具,还支持流式 TTS API 接口。
1. 系统环境
操作系统:Ubuntu 22.04 是在 ucloud 租的 GPU 服务器,4090 48G 显存魔改版
(GPTSoVits) ubuntu@10-60-55-82:~/hou/GPT-SoVITS$ neofetch
.-/+oossssoo+/-.
`:+ssssssssssssssssss+:`
-+ssssssssssssssssssyyssss+- ubuntu@10-60-55-82
.ossssssssssssssssssdMMMNysssso. ------------------
/ssssssssssshdmmNNmmyNMMMMhssssss/ OS: Ubuntu 22.04.4 LTS x86_64
+ssssssssshmydMMMMMMMNddddyssssssss+ Host: KVM UCLOUD 1.0.0 O PC (i440FX + PIIX, 1996)
/sssssssshNMMMyhhyyyyhmNMMMNhssssssss/ Kernel: 5.15.0-113-generic
.ssssssssdMMMNhsssssssssshNMMMdssssssss. Uptime: 5 days, 46 mins
+sssshhhyNMMNyssssssssssssyNMMMysssssss+ Packages: 1892 (dpkg), 7 (snap)
ossyNMMMNyMMhsssssssssssssshmmmhssssssso Shell: bash 5.1.16
ossyNMMMNyMMhsssssssssssssshmmmhssssssso Terminal: node
+sssshhhyNMMNyssssssssssssyNMMMysssssss+ CPU: INTEL XEON GOLD 6530 (16) @ 2.100GHz
.ssssssssdMMMNhsssssssssshNMMMdssssssss. GPU: NVIDIA 00:03.0 NVIDIA Corporation Device 2684
/sssssssshNMMMyhhyyyyhdNMMMNhssssssss/ Memory: 26044MiB / 96553MiB
+sssssssssdmydMMMMMMMMddddyssssssss+
/ssssssssssshdmNNNNmyNMMMMhssssss/
.ossssssssssssssssssdMMMNysssso.
-+sssssssssssssssssyyyssss+-
`:+ssssssssssssssssss+:`
.-/+oossssoo+/-.
(GPTSoVits) ubuntu@10-60-55-82:~/hou/GPT-SoVITS$ nvidia-smi
Tue Aug 12 09:29:00 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.133.07 Driver Version: 570.133.07 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:00:03.0 Off | Off |
| 63% 29C P8 24W / 450W | 10430MiB / 49140MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 525763 C ...da/envs/python310/bin/python3 2116MiB |
| 0 N/A N/A 526094 C python 674MiB |
| 0 N/A N/A 526095 C python 688MiB |
| 0 N/A N/A 526111 C python 4326MiB |
| 0 N/A N/A 526205 C ...t/build/bin/funasr-wss-server 2596MiB |
+-----------------------------------------------------------------------------------------+2. 项目安装
项目克隆到本地后,需要安装项目依赖和下载模型文件,直接使用 install.sh即可:
# 创建虚拟环境
conda create -n GPTSoVits python=3.10
conda activate GPTSoVits
# 安装
(GPTSoVits) ubuntu@10-60-55-82:~/hou/GPT-SoVITS$ bash install.sh --device CU128 --source HF-Mirror
[INFO]: Detected system: Linux 5.15.0-113-generic x86_64
[INFO]: Detected GCC Version: 11
[INFO]: Skip Installing GCC & G++ From Conda-Forge
[INFO]: Installing libstdcxx-ng From Conda-Forge
[SUCCESS]: libstdcxx-ng=11 Installed...
[INFO]: Installing FFmpeg & CMake...
[SUCCESS]: FFmpeg & CMake Installed
[INFO]: Installing unzip...
[SUCCESS]: unzip Installed
[INFO]: Download Model From HuggingFace-Mirror
[INFO]: Downloading Pretrained Models...
[SUCCESS]: Pretrained Models Downloaded
[INFO]: Downloading G2PWModel..
[SUCCESS]: G2PWModel Downloaded
[INFO]: Checking For Nvidia Driver Installation...
\033[1;32m[INFO]: \033[0mNvidia Driver Founded
[INFO]: Installing PyTorch For CUDA 12.8...
[SUCCESS]: PyTorch Installed
[INFO]: Installing Python Dependencies From requirements.txt...
[SUCCESS]: Python Dependencies Installed
[INFO]: Downloading NLTK Data...
[SUCCESS]: NLTK Data Downloaded
[INFO]: Downloading Open JTalk Dict...
[SUCCESS]: Open JTalk Dic Downloaded
[SUCCESS]: Installation Completed3. 启动 & 微调
3.1 项目启动
在项目根目录下启动 web 界面,使用中文
python webui.py zh_CN3.2 数据集准备
准备好 wav 格式的语音数据集和对应的文字
准备 dataset.list 文件
文件格式如下:
语音路径 | 说话人名称 | 语音语言 | 语音内容我的文件内容:
准备了六条纳西妲的语音数据
/home/ubuntu/hou/GPT-SoVITS/data/gpt/1.wav|naxida|zh|小猫也想变成狐狸,但它尾巴太细小,又长不出富有色彩的皮毛。其他狐狸见了,安慰道:就算如此,你也是我们的同伴。
/home/ubuntu/hou/GPT-SoVITS/data/gpt/2.wav|naxida|zh|怪兽厌恶这种美满,在山中点起一把火。动物们异常惊慌。为了扑灭大火,它们必须做出牺牲。
/home/ubuntu/hou/GPT-SoVITS/data/gpt/3.wav|naxida|zh|一只灰色的狐狸站起来,与怪兽交谈。它说:你是如此聪明,一定能想到帮助我们的办法。
/home/ubuntu/hou/GPT-SoVITS/data/gpt/4.wav|naxida|zh|怪兽将那颗水珠交给小猫,告诉它:大家已经想好让你牺牲了。带上这个,去为你的狐狸同伴而死吧。
/home/ubuntu/hou/GPT-SoVITS/data/gpt/5.wav|naxida|zh|它们说好要相依为命,可小鸟的寿命太短,一下就没了呼吸。小猫埋葬它之后,便离开了那座山。
/home/ubuntu/hou/GPT-SoVITS/data/gpt/6.wav|naxida|zh|…它再也没有爱过山中任何一片树叶与任何一只动物。它流浪在每一个夜晚,对着月光磨牙。3.3 微调
3.3.1 训练集格式化
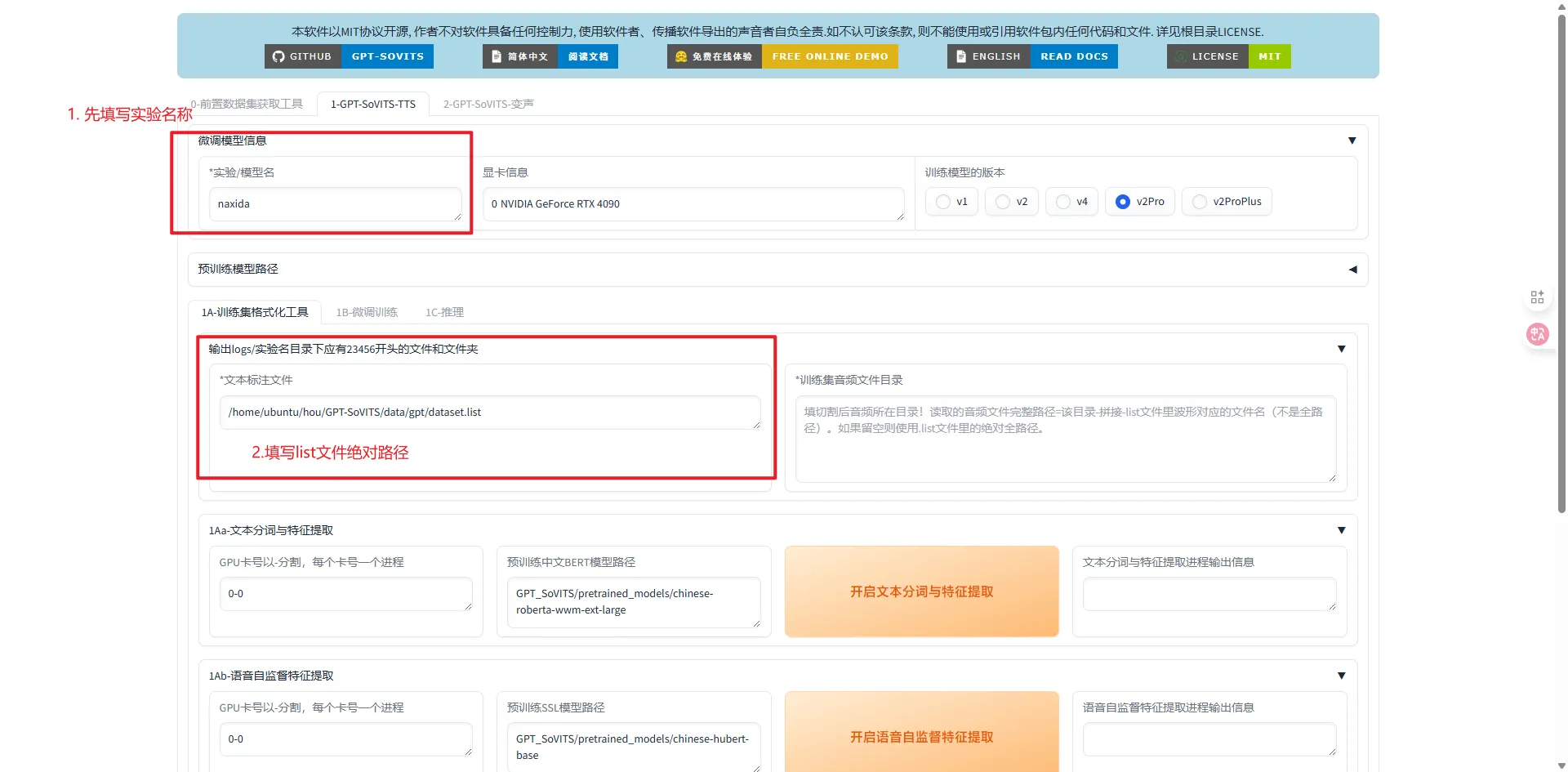
- 填写实验名称
- 填写 list 文件绝对路径
- 训练集格式化一键三连,然后观察右下角的输出,等待出现一键三连完成提示
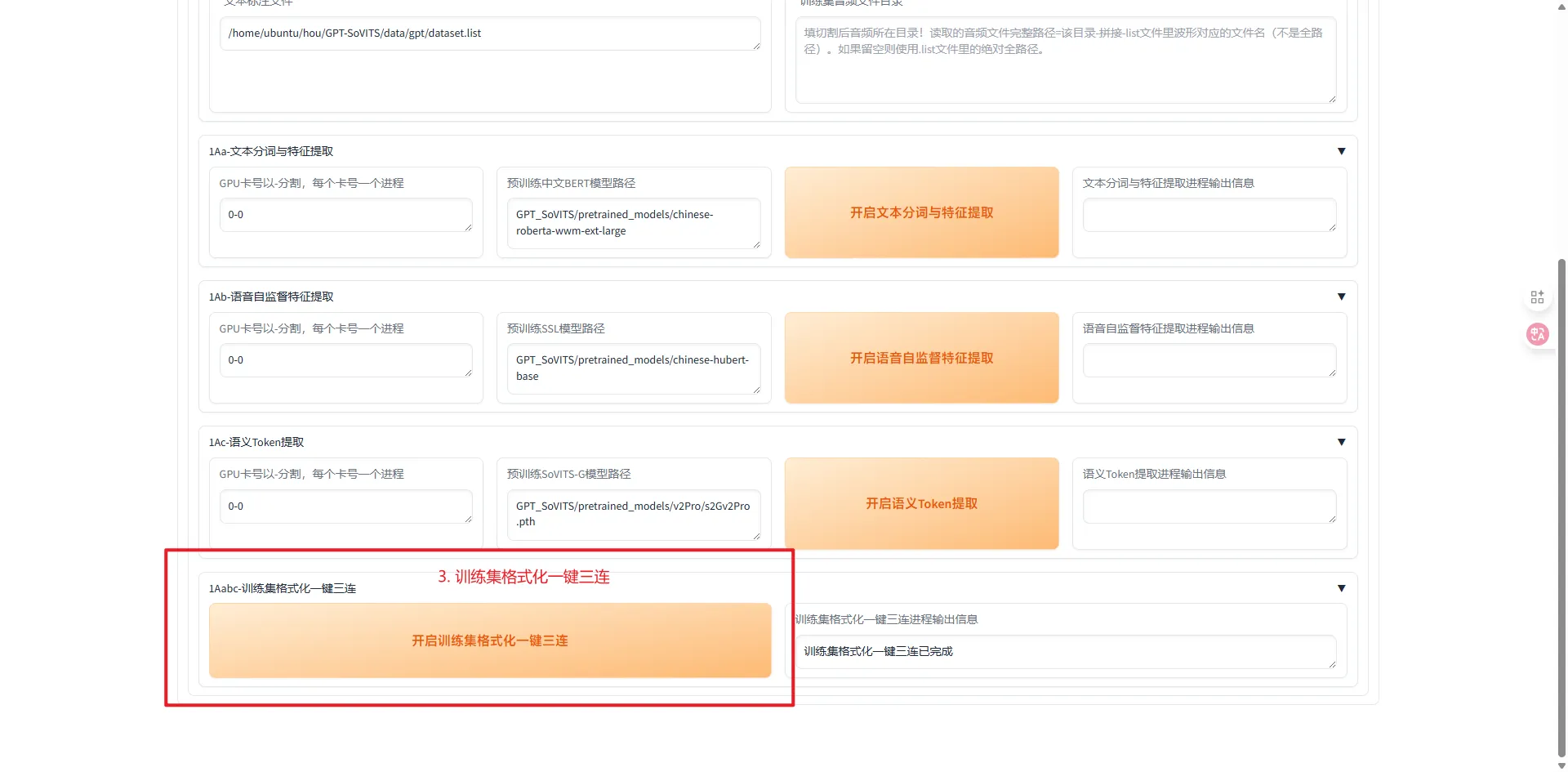
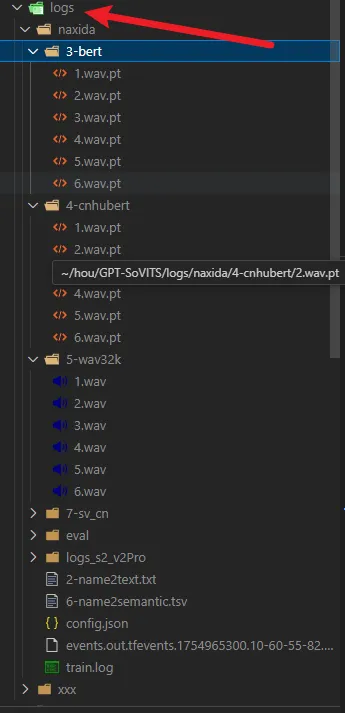
格式化后,会在 logs/实验名称 这个文件夹下有对应的数据
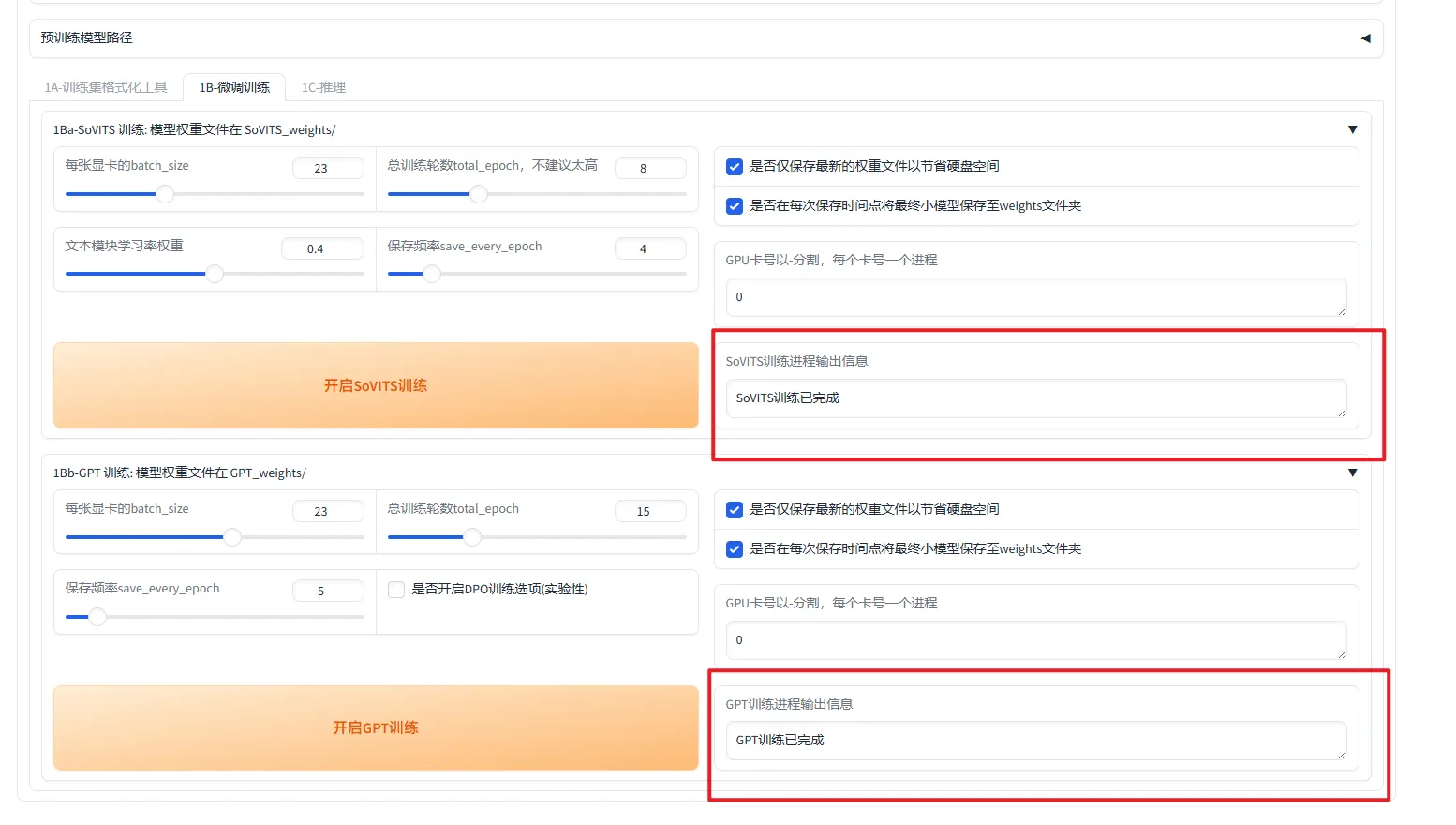
3.3.2. 微调训练
- 先点击开启 SoVITS 训练,等待出现 SoVITS 训练完成后
- 再点击开启 GPT 训练,等待训练完成
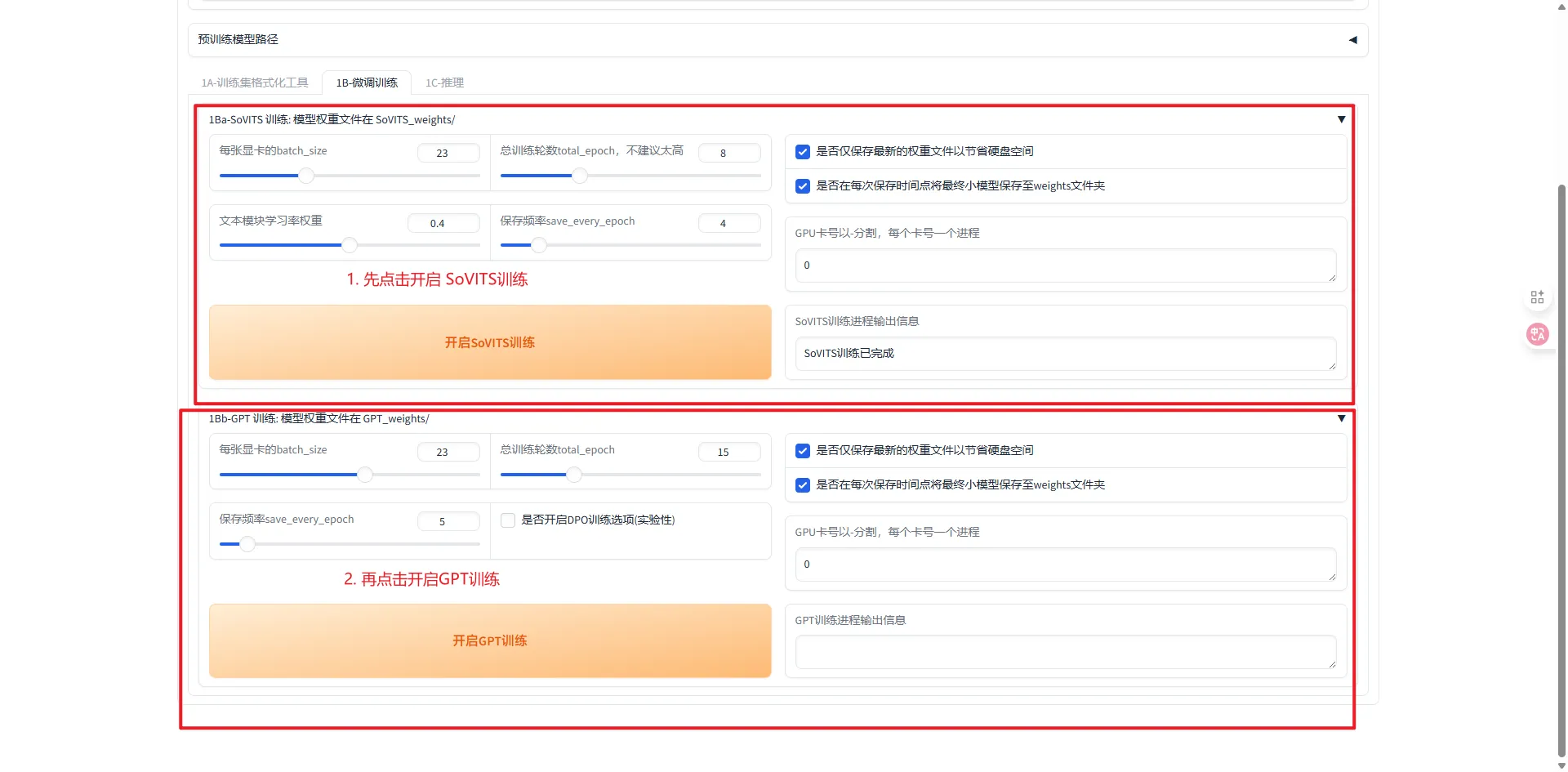
训练完成示意图
4. 推理
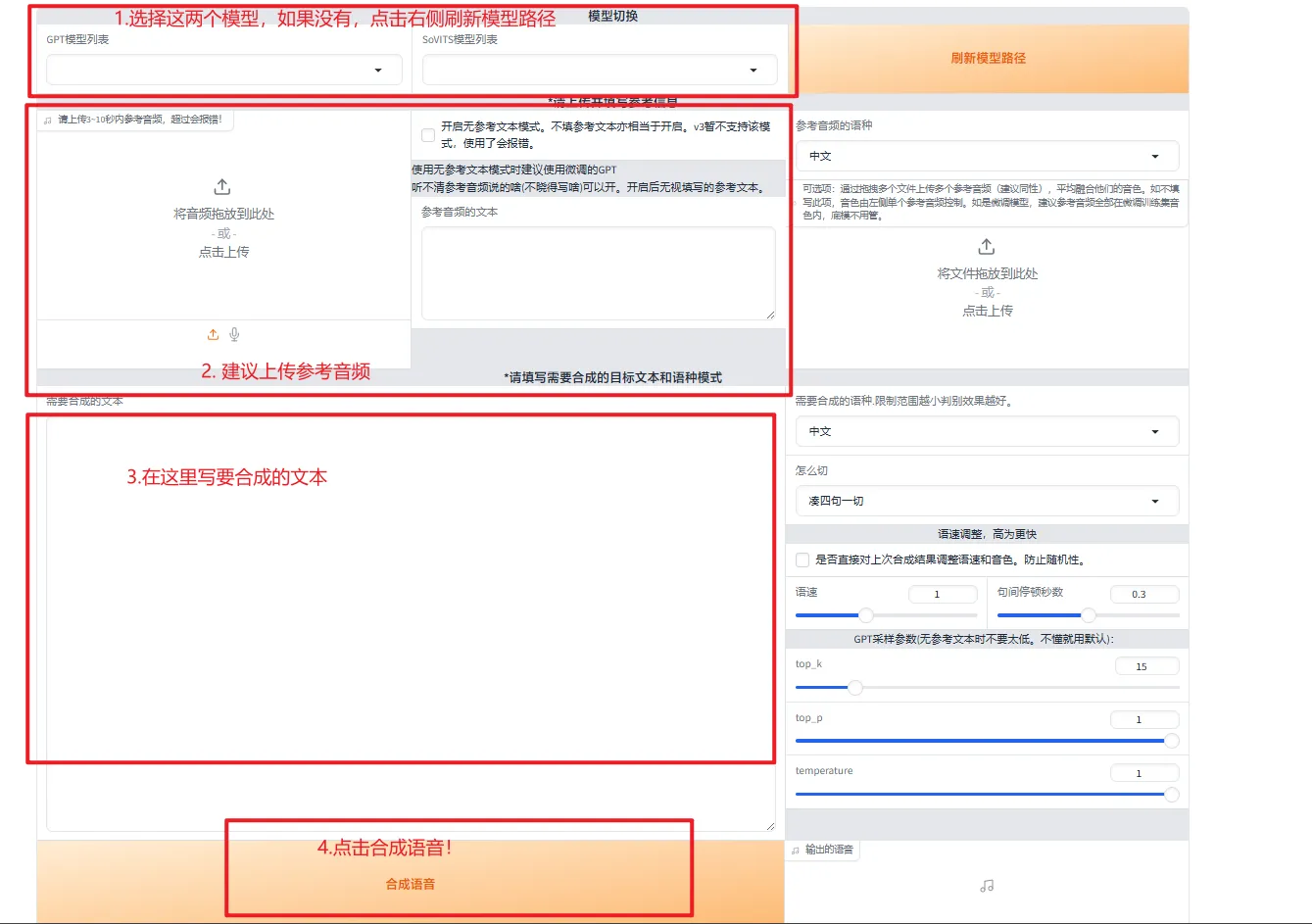
点击开启 TTS 推理,会跳出如下页面:
- 先选择模型
- 上传参考音频和对应的参考文本
- 填写要合成的文本
- 点击合成语音
5. API 模式
5.1. 启动
微调好模型肯定需要 API 调用
执行 api.py 文件
python api.py -s SoVITS_weights_v2ProPlus/naxida-v2proplus_e8_s48.pth -g GPT_weights_v2ProPlus/naxida-v2proplus-e15.ckpt-s 是指定 SoVITS 模型
-g 是指定 gpt 模型
执行完成后这就代表成功启动
(GPTSoVits) ubuntu@10-60-55-82:~/hou/GPT-SoVITS$ python api.py -s SoVITS_weights_v2ProPlus/naxida-v2proplus_e8_s48.pth -g GPT_weights_v2ProPlus/naxida-v2proplus-e15
.ckpt
INFO: 未指定默认参考音频
INFO: 半精: True
INFO: 编码格式: wav
INFO: 数据类型: int16
INFO: 模型版本: v2ProPlus
INFO: Started server process [947648]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:9880 (Press CTRL+C to quit)5.2. 接口文档
访问网址:http://localhost:9880/docs
这里是接口文档
5.3. TTS 接口(GET)
现在可以通过 api 文字转语音了!
主要填写三部分
- 参考音频、文本和语言
- 要生成的文本和语言
- 默认推理参数
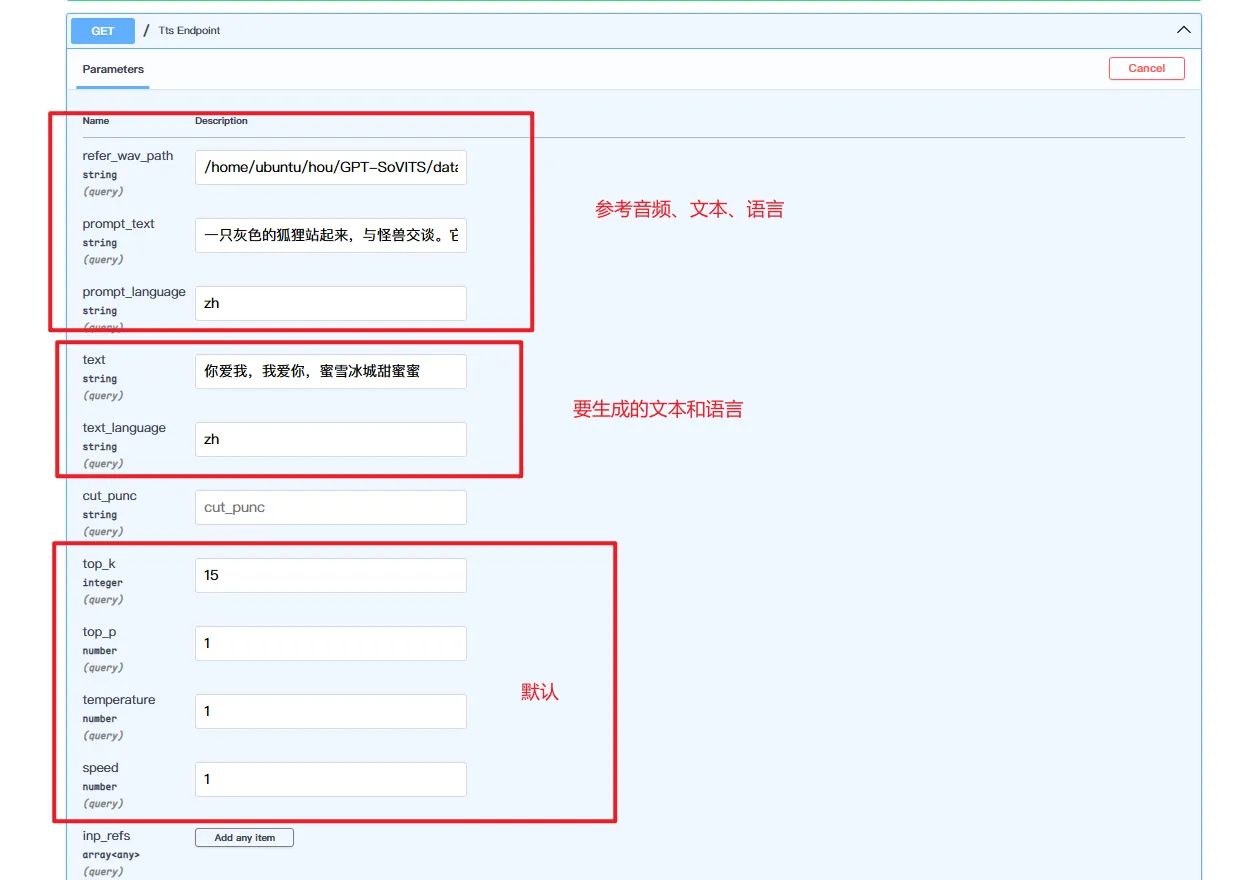
点击 execute 之后,就可以看到生成的语音文件了
5.4. 流式 TTS 接口
启动的时候添加流式的参数即可
-sm:流式返回模式, 默认不启用, 可以设置为如下值”close”,“c”, “normal”,“n”, “keepalive”,“k”
-mt:返回的音频编码格式, 流式默认ogg, 非流式默认wav, “wav”, “ogg”, “aac”
测试 ogg,浏览器运行报错了,所以使用 aac 格式
python api.py -s SoVITS_weights_v2ProPlus/naxida-v2proplus_e8_s48.pth -g GPT_weights_v2ProPlus/naxida-v2proplus-e15.ckpt -sm k -mt aac配置跨域,修改 api.py 文件
在 main 上面添加如下代码
# 新增代码
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 下面是原有代码
if __name__ == "__main__":
uvicorn.run(app, host=host, port=port, workers=1)可以使用 post 接口来请求,以下是流式测试用的 html 代码
<!doctype html>
<html lang="zh-CN">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width,initial-scale=1" />
<title>流式 TTS 播放器 (POST JSON)</title>
<style>
body {
font-family: -apple-system, BlinkMacSystemFont, Segoe UI, Roboto, "Helvetica Neue", Arial;
margin: 20px;
background: #0f172a;
color: #e6eef8
}
.card {
background: #111827;
padding: 18px;
border-radius: 10px;
box-shadow: 0 6px 18px rgba(2, 6, 23, .6);
max-width: 820px;
margin: auto
}
textarea,
input,
select,
button {
width: 100%;
margin-top: 8px;
padding: 8px;
border-radius: 8px;
border: 1px solid #23303b;
background: #071022;
color: #e6eef8
}
button {
cursor: pointer;
background: #1e293b
}
.row {
display: flex;
gap: 8px;
margin-top: 10px;
flex-wrap: wrap
}
.log {
margin-top: 12px;
background: #04101a;
padding: 10px;
border-radius: 6px;
height: 120px;
overflow: auto;
font-size: 13px
}
</style>
</head>
<body>
<div class="card">
<h2>流式 TTS 播放器 (POST JSON)</h2>
<label>TTS 接口 URL</label>
<input id="ttsUrl" value="http://127.0.0.1:9880" />
<label>Refer WAV 路径</label>
<input id="referWav" value="/home/ubuntu/hou/GPT-SoVITS/data/gpt/ref.wav" />
<label>Prompt 文本</label>
<textarea id="promptText">我还有些事要研究,你们先转换一下心情吧。</textarea>
<label>Prompt 语言</label>
<input id="promptLang" value="zh" />
<label>合成文本</label>
<textarea id="text">欢迎使用我们的语音合成服务。</textarea>
<label>文本语言</label>
<input id="textLang" value="zh" />
<label>切分标点</label>
<input id="cutPunc" value=",。!?" />
<div class="row">
<select id="mediaType">
<option value="ogg">ogg</option>
<option value="aac">aac</option>
<option value="wav">wav</option>
</select>
<button id="startBtn">开始播放</button>
<button id="stopBtn" disabled>停止</button>
</div>
<audio id="player" controls style="width:100%;margin-top:10px"></audio>
<div class="log" id="log"></div>
</div>
<script>
const logEl = document.getElementById('log');
function log(...args) {
console.log(...args);
logEl.innerText += args.join(' ') + '\n';
logEl.scrollTop = logEl.scrollHeight;
}
let controller = null;
let reader = null;
let mediaSource = null;
let sourceBuffer = null;
let queue = [];
let audioUrl = null;
let playingBlobParts = [];
const startBtn = document.getElementById('startBtn');
const stopBtn = document.getElementById('stopBtn');
const player = document.getElementById('player');
startBtn.addEventListener('click', startStreaming);
stopBtn.addEventListener('click', stopStreaming);
async function startStreaming() {
stopStreaming();
const baseUrl = document.getElementById('ttsUrl').value.trim();
const mediaType = document.getElementById('mediaType').value;
const bodyData = {
refer_wav_path: document.getElementById('referWav').value.trim(),
prompt_text: document.getElementById('promptText').value,
prompt_language: document.getElementById('promptLang').value.trim(),
text: document.getElementById('text').value,
text_language: document.getElementById('textLang').value.trim(),
cut_punc: document.getElementById('cutPunc').value
};
log('POST 请求:', baseUrl, bodyData);
controller = new AbortController();
queue = [];
playingBlobParts = [];
if ('MediaSource' in window && mediaType === 'ogg') {
setupMediaSource('audio/ogg; codecs="opus"');
fetchAndStreamPOST(baseUrl, bodyData, controller.signal, true);
} else if ('MediaSource' in window && mediaType === 'aac') {
setupMediaSource('audio/aac');
fetchAndStreamPOST(baseUrl, bodyData, controller.signal, true);
} else {
fetchAndPlayAsBlobPOST(baseUrl, bodyData, controller.signal);
}
}
function setupMediaSource(mime) {
cleanupMediaSource();
mediaSource = new MediaSource();
audioUrl = URL.createObjectURL(mediaSource);
player.src = audioUrl;
mediaSource.addEventListener('sourceopen', () => {
try { sourceBuffer = mediaSource.addSourceBuffer(mime); } catch (e) { log('addSourceBuffer 失败:', e); return; }
sourceBuffer.mode = 'sequence';
sourceBuffer.addEventListener('updateend', () => {
if (queue.length > 0 && !sourceBuffer.updating) {
const chunk = queue.shift();
sourceBuffer.appendBuffer(chunk);
} else if (queue.length === 0 && mediaSource.readyState === 'open' && !reader) {
mediaSource.endOfStream();
}
});
if (queue.length > 0 && !sourceBuffer.updating) {
const chunk = queue.shift();
sourceBuffer.appendBuffer(chunk);
}
player.play().catch(() => { });
});
}
function cleanupMediaSource() {
if (sourceBuffer) { try { if (mediaSource && mediaSource.readyState === 'open') mediaSource.removeSourceBuffer(sourceBuffer); } catch (e) { } sourceBuffer = null; }
if (mediaSource) { try { URL.revokeObjectURL(audioUrl); } catch (e) { } mediaSource = null; }
}
async function fetchAndStreamPOST(url, body, signal, useMediaSource) {
const resp = await fetch(url, { method: 'POST', signal, headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(body) });
if (!resp.ok) throw new Error('HTTP ' + resp.status);
const ct = resp.headers.get('content-type') || '';
if (ct.includes('application/json')) { throw new Error('Server error: ' + JSON.stringify(await resp.json())); }
reader = resp.body.getReader();
stopBtn.disabled = false;
startBtn.disabled = true;
while (true) {
const { done, value } = await reader.read();
if (done) break;
if (!value) continue;
const chunk = value.buffer.slice(value.byteOffset, value.byteOffset + value.byteLength);
playingBlobParts.push(chunk);
if (useMediaSource && sourceBuffer) {
if (sourceBuffer.updating || queue.length > 0) { queue.push(chunk); }
else { try { sourceBuffer.appendBuffer(chunk); } catch (e) { queue.push(chunk); } }
}
}
log('流读取结束');
reader = null;
stopBtn.disabled = true;
startBtn.disabled = false;
if (!useMediaSource) {
const mime = resp.headers.get('content-type') || 'audio/ogg';
const blob = new Blob(playingBlobParts, { type: mime });
player.src = URL.createObjectURL(blob);
player.play().catch(() => { });
}
}
async function fetchAndPlayAsBlobPOST(url, body, signal) {
log('fallback -> blob 下载');
const resp = await fetch(url, { method: 'POST', signal, headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(body) });
if (!resp.ok) { log('HTTP error', resp.status); return; }
const ct = resp.headers.get('content-type') || 'audio/ogg';
const ab = await resp.arrayBuffer();
const blob = new Blob([ab], { type: ct });
player.src = URL.createObjectURL(blob);
player.play().catch(() => { });
stopBtn.disabled = false;
startBtn.disabled = true;
}
function stopStreaming() {
try { if (controller) controller.abort(); } catch (e) { }
controller = null;
if (reader) { try { reader.cancel(); } catch (e) { } reader = null; }
cleanupMediaSource();
try { if (player.src && player.src.startsWith('blob:')) URL.revokeObjectURL(player.src); } catch (e) { }
player.pause();
stopBtn.disabled = true;
startBtn.disabled = false;
log('已停止');
}
</script>
</body>
</html>测试效果
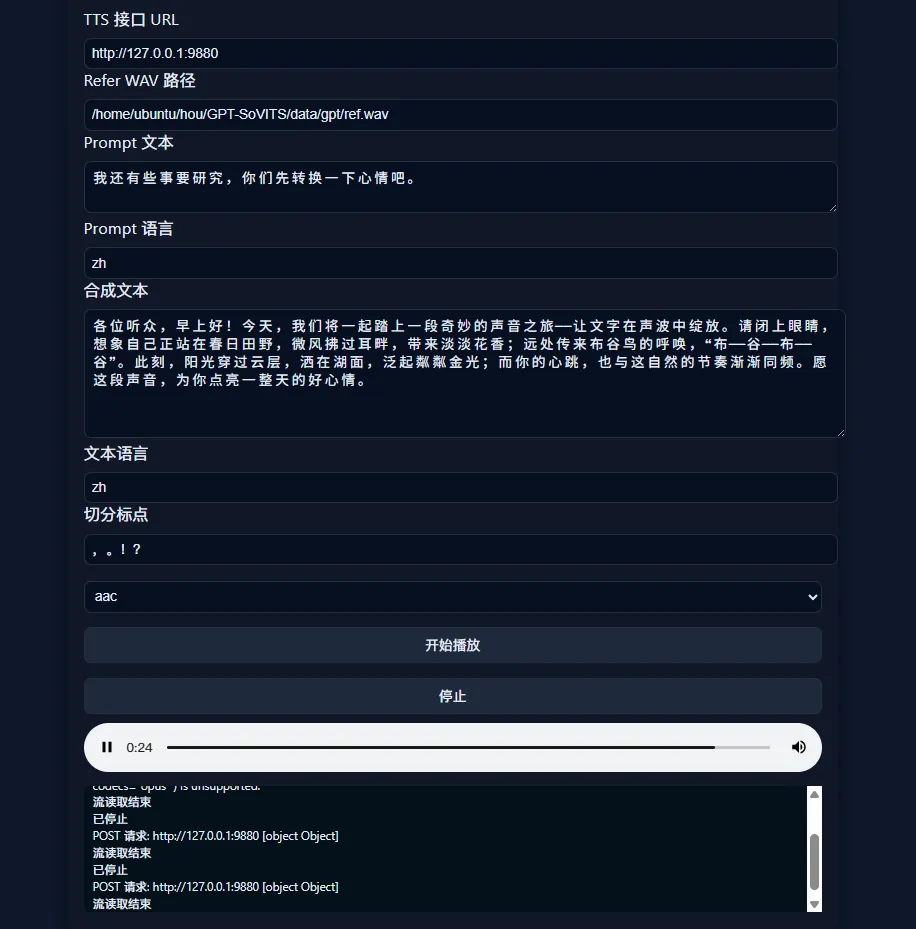
测试文本
各位听众,早上好!今天,我们将一起踏上一段奇妙的声音之旅——让文字在声波中绽放。 请闭上眼睛,想象自己正站在春日田野,微风拂过耳畔,带来淡淡花香; 远处传来布谷鸟的呼唤,“布——谷——布——谷”。此刻,阳光穿过云层,洒在湖面,泛起粼粼金光; 而你的心跳,也与这自然的节奏渐渐同频。愿这段声音,为你点亮一整天的好心情。
155 字的情况下:
- 非流式:10s 生成完毕
- 流式: 6s 后开始传输语音
语音长度 37s
简单测试,仅供参考,测试显卡 NVIDIA GeForce RTX 4090 48G 显存
6. 存在问题
6.1. 必须得上传参考音频
按照说明,理论上来说可以不填写参考音频和文本(可以打对勾无参考音频模式),使用微调后的模型来直接推理,但是试了 v1、v2、v2pro、v2proplus,v4 都必须得上传音频
其中 v4 是无法开启无参考音频模式
其他版本可以开启无参考音频模式,但是报错提示需要上传参考音频